Open Data v3.0 Permissive Commons
Why the open data movement needs a facelift, and how that might be done.

** ‘privacy vs. dignity’ and the nuances to be made between ‘open data’ and ‘permissive commons’ ** Image source: Facebook https://www.facebook.com/IMissAustraliaGrewUpIn/
The open data movement is perhaps the most instrumental activity type, on the web, for the pursuit of humanitarian advancement. Without open-data, it would be hard to forge or foster, the means to make sense of anything.
The wikipedia entry for OpenData explains the concept in the following way;
Open data is the idea that some data should be freely available to everyone to use and republish as they wish, without restrictions from copyright, patents or other mechanisms of control.[1] The goals of the open-source data movement are similar to those of other “open(-source)” movements such as open-source software, hardware, open content, open education, open educational resources, open government, open knowledge, open access, open science, and the open web.
In many ways, the open-data movement sought to create an online equivalent to the availability of public libraries. Yet there are emergent problems, and opportunities — which brings about my considerations for how this instrumental movement might benefit from a facelift.
To distinguish between the two similar concepts, i introduce this concept of ‘permissive commons’.
Open data has been slowly uplifted to support software agents, as to support AI. These sorts of practices have been canvassed in an earlier post about Tools that can help naturalise the web which in-turn relates also to my post about ‘knowledge clouds’.
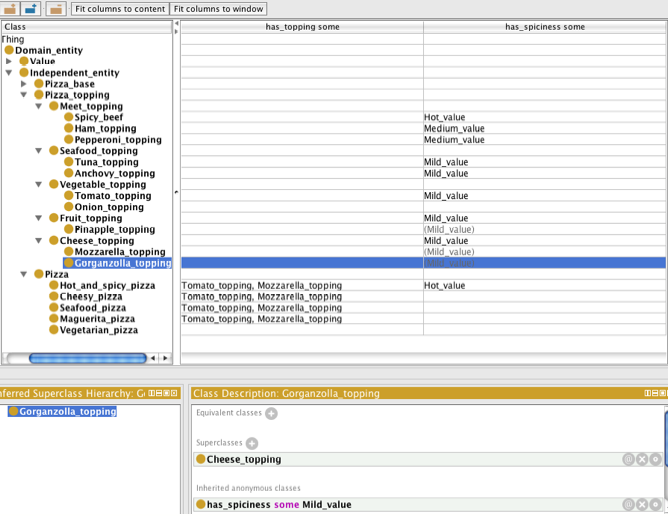
Pizza Ontology source: Protege
In someways, the considerations about ‘knowledge clouds’ could also be thought about in the form of knowledge trees & forests.
Th Researchspace video below, illustrates these ‘knowledge clouds’ practice theory, in a manifest illustration of its meaningful utility for studies of history.
The difference between this ‘permissive commons’ approach and the research space illustration; is that permissive commons seeks to build these capacities into a commons web, by using semantic web technologies in a particular way.
This distinct advantage brought about through the use of semantic web technologies and ecosystems; as apposed to other notation methods, is that works become both machine (AI) & human readable; and, if well designed, are able to be employ decentralised informatics outcomes, permissively.
Another way to visualise some components of how this works, can be visualised by testing out mind-mapping software; whilst considering the opportunity to interlink maps or trees made in communities and other attributes such as temporal considerations are hard to see in a mind-map.
A permissive commons approach is formed by defining Semantic ontologies.
Jason Silva: Shots of Awe — What is Ontological Design?
Therein; there is an important difference between the term common and commons, in a similar way to the distinction between civic and civics, whilst both are important.
My work on Web Civics; is about fostering civilian participation WITH governments; rather than for government. Therein, “web civic” would be some sort of government owned thing, perhaps like a library, but web civics, is about fostering the importance role of civilians, citizens, to contribute. The idea being that practice of undertaking civics should be an inclusive practice with governments, the underlying context is that the role of citizens is important.
Without access to; and beneficial use of, knowledge, the means maintain personhood and therefore the meaningful value of citizenship, is made mute.
The practice of commons or commoning as is distinct to ‘open’, considers the reality that most things (concepts, spaces, resources) are made permissively available to an intended group of people via means that incorporate custodial considerations to support the creation, governance and management of the common resources made to be part of a specified commons.

If we consider the role of ‘open data’ in association to the DIKW Pyramid; then my explanation somewhat goes as follows,
Data is bits of information, but not information itself. Information is in-essence, refined forms of data, made to be helpful to understand the some intended meaning.
Fake news, is information, but does not provide knowledge about the event or subject the fake news article talks about. Knowledge may be defined as relevant and objective information that helps in drawing conclusions (about the real world).
The purpose of improving upon the concept of ‘open data’ to ‘permissive commons’ in-effect seeks to forge a foundry for human activities to be put to the task of forging commons knowledge services that are able to be relied upon by other agents; ideally, in a ‘human centric’ approach, which would make other ‘artificial agents’ (software agents, company agents) servants of natural agents, and groups forged by natural agents as is made representative.
whilst noting the means to do so, would likely be best carried out using permissive commons, that in-turn provide support to form and maintain contracts online, and some existing work such as creative commons, illustrates works in the field
Historical examples of commons
Older (real-world) examples might make this easier to understand.
For example;
Farmers
a group of farmers may cooperatively bring about the availability of a processing plant or storage facility for shared use as a commons facility. Yet this infrastructure is not intended to be entirely ‘free’, the facility has a governance framework and a group of intended beneficiaries,
As such, if some entrepreneur wanted to import competing resources to store in these facilities at the expense of farmers — that would not be allowed.
Yacht Club
Similarly, a yacht-club might have a yard and a crane to help take a boat in and out of the water, and to make repairs; but it’s not able to be used to pull a motor out of vehicle or some other unintended purpose.
Therein — whilst many things are beneficially ‘commons’, their not “freely available to everyone to use and republish (or repurpose) as they wish”
The second issue is that of economic governance.
Whilst many prefer the fantasy that things on the internet are truely free, this idea has no reliable foundation in reality. From the energy consumed to make computers work, to the resources invested in the manufacture of devices inter-networked on the web; and perhaps more importantly than most consider, the cost of life, as has been incurred by those who do some sort of work to foster growth both of the resources available on the web, and the means of online works to positively impact something that belongs to our biosphere, in some way (not always)…
Free, doesn’t actually exist. Without attribution, workers making things for ‘free’ are actually paying themselves to do something, without acknowledgement.
Whilst this sort of framework has played a significant role for the creation of many good things; it is also instrumentally responsible for a great deal of bad and sometimes unintended outcomes.
The worst examples are those that show how this manifest well accepted practice of ‘web slavery’ has in-effect been weaponised as a cyber warfare tool.
Thereafter; Considerations of how ‘open data’ has been deployed shows that in reality there are actually very few known ‘trusted’ (whether trust-worthy or not) domain-name based sources (and underlying company structures) who are now the international gatekeepers to the bewildering store of (human) knowledge. This is in-turn considered to have some form of meaningful relationship between the relatively misleading concept defined as ‘open data’, and what may be improved upon as ‘permissive commons’, as to attach semantics relating to informatics and progress towards a knowledge age.
Whereas; in todays ‘open data’ movement powering the ‘information age’,
- Whilst some websites aren’t very good due to a lack of available funding; and
- others continually make requests for donations; whilst a handful of others,
- act to support as beneficiaries; the largest corporations in the world.
The greatest beneficiaries of the well-intended and vitally important ‘open data movement’ is this handful companies, who positioned themselves as the communications and knowledge gatekeepers.
Having forged ‘golden handcuffs’ by owning the search-box, or a persons address book; these multi-billion dollar companies are now all too often associated with gainful incomes associated to nefarious actors and the ‘information’ they peddle for money that includes; fake news, spam and a great deal more. Making matters worse, the ontological vocabularies most used on the internet today refer to object definitions of well known words for specified purpose as to sell things.
The easiest way to example this, is how the system used by search giants; Google, Microsoft, Yahoo, Yandex, etc. defines such things as a Physician.

schemaorg to populate search results and support the growth and development of AI, defines the term Physician as a place, rather than person or profession.
Whilst it is understandably the case that the reason why this occurs is that the purpose of this vocabulary (which may be repurposed for many other applications, by trained or untrained producers) is to assist with discovering information on maps — the ability to find a doctors office.
The other relatively well characterised issue is that these systems now lack the ability to identify objects about the world, that have no financial incentive to illustrate. As is otherwise illustrated below; it is now easier to find a toilet by searching for the nearest McDonalds restaurant, due to the lack of ontology.
This predicament influences the manifest nature of how Artificial Intelligence Agents (software agents) are made to (be able to) work.
If we have an informatics environment that are centrally governed, on an international basis supporting ‘sense making’ capacities for all things; then the means to support ‘privacy’ or moreover dignity, is entirely undermined.

Diagram i’ve authored previously about human centric web ecosystems | In relation to my blog post on webizen re: SOCIO-ECONOMIC RELATIONS | A CONCEPTUAL MODEL
As a consequence of my design considerations towards the manifestation of a human centric web; one of the important functional requirement is the need to reliably obtain ‘commons’ informatics (data/information/knowledge) that can then be locally consumed in relation to the means for a machine-processed query (ie: AI function) to have the informatics-resources it needs available to it, to perform its basic functions, privately.
The alternative used today is generally provided as a domain based API, but this means the capacity to perform the query privacy is dependent upon them.

source: reddit
The Open Data movement has brought about a somewhat exceptional ‘open data charter’ that provides a set of objective needs that are of most importance for society via the lens of open data. My thoughts on permissive commons seek to uplift the spirit of these principles, as to support the manufacture of improved apparatus, as to put them to better use.
Whilst it is ‘common sense’ that the principle of instrumental importance is the need to ensure read permissions (mostly) stay open; i’ll have to explain why i say ‘mostly’ and not always, in consideration of the fact that not-everyone needs to know everything; but this in-turn causes a ripple effect.
Introducing Permissive Commons: a technical architecture overview
Breaking down the parts, i’ll make some high-level notes about what i mean by permissive, and implicitly therein permissions; methods to support discoverability, decentralisation and custodianship. Whilst this methodology is designed to support the way systems work today; it’s also, and perhaps more importantly considering future needs, which i’ll briefly review also
1. Permissions to support permissive use.
Permissions from a perspective of technical apparatus; refers to the means for an agent to create, edit, read and append informatics resources or part of them. Commonly linked to the concept of CRUD (create, read, update, delete); permissioning systems offer a means to distinguish roles in relation to informatics resources. Another way of looking at permissions in a networked environment; is the idea of Attribute-based Access Control.
If this is considered in the context of systems that support version control, such as Git (as is distinct to Github); counterpart qualities brought about include; the ability to,
- To target a specific version by a specified publisher / authority
- ‘fork’ a version, update, make changes and re:publish as an alternate publisher / authority
- Curate versions between authorities as coupled or decoupled resources
- Reference related resources, for inferencing solutions, whilst retaining resolution of provenance and trust related semantic qualities.
This series of permission related considerations are important for supporting means to append, support versions and linked assets that are made to be connected to the original ‘piece’ of data that is not generically associated to ‘open data’ solutions today. A way this can be illustrated through the lens of documents; is in-turn, the subject of a life-long field of work by Ted Nelson.
Xanadu Space by Ted Nelson
The video by Ted illustrates the relationships between pieces of knowledge, fairly well. Yet therein, the way this is managed is through some form of authentication. The vast majority of web-use is now performed with the support of a few types of authentication, whilst the operational consumption of online material is not connected to a natural persons identity (at least not in a way that’s there for all to see).
Not everyone, needs to know everything
In the vast majority of use-cases, ‘Open’ read permissions are amongst the most important qualities that are required to uplift ‘open data’ intents; and any potential means to deliver better formats, as is the intent of this ‘permissive commons’ theory. Therein; the means to maintain the capacity to identify how an interaction with something has been influenced by others — becomes somewhat essential for ‘sense making’ with cyber-commons resources, that are intended to support cyber-physical systems.
It is also important to consider the differentiated means for ‘sense making’ between those who do not have permission; and those who do. If a natural agent makes mistakes in reliance of the best available information they have available to them; this is very different to those how do the same, in a circumstance where it is clearly known to them, reality shows otherwise.
Considering the effect of this overtime; as is instrumentally known as learning, the knowledge of all things develops overtime; both individually, socially and globally, as may relate to the knowledge of all mankind.
Therein; one might consider use-cases that relate to health and medicine.
The health-sciences field today, has a well-established ecosystem of available ontologies; yet present means for patients to play a better role is made hard.
Social Sciences & Medical Research
Within the concept of permissive commons, is the consideration that some agents (actors) may not need the point-data, which is the exacting audit ready, otherwise ‘open’ record that relates to the useful embodiment of some sort of dataset, information asset / knowledge.
If researchers are doing work attempting to address a critical medico-legal / societal issue; such as suicide, there’s a bunch of informatics about a persons life (and the end of it), alongside useful informatics about relations to others socially surrounding a case; that if collected, collated and summarised, as to be provided as an anonymised dataset for researchers, could make it possible for outcomes to be found where it would be otherwise impossible to do so.
But the implications of these sorts of things associates directly to privacy; or moreover dignity considerations that may well affect children amongst others.
To ensure research is being carried out upon real data, and not made-up circumstances that may better suit aversions to inconvenient facts; the underlying data does in-fact need to have a means to be audited. An Audit function could be supported by a nominated authorised agent or agency, who could be equipped to support auditing services — much like an Accountant.
This process does not need to be public or made globally (or locally) centralised.
Meanwhile; large ‘data lakes’ (or knowledge banks) could aggregate informatics permissively from its customers as to generate anonymised summary results and insights; and/or, furnish means to act in a federated activity to perform specified queries across participant frameworks, privately; providing outputs as commons.
Similarly; specifically tailored agents could be produced to operate permissively with special interest groups; such as, people who suffer from a particular disease, ailment or health problem. Informatics could be curated for use by their medical clinicians, alongside derivative informatics products for researchers that are created by collating informatics via specified data-structures, from many people.
In other less sensitive areas of ‘open data’ policy; these types of practices are already readily used; Whether it be the availability of economic data or (almost) any other area of statistics, summaries are provided publicly; the underlying ‘point data’, not at all.
Yet a problem that today’s open-data movement hasn’t been able to resolve where it comes to analysis of social issues (for instance); is that the data collected can be from a relatively small study, as such the quality of the derivative materials become less reliable and is often also vexed with an array of other issues that relates to who did the study and for what purpose.
Cyber Knowledge Systems
The issues that are exhibited in fields such as statistics or research; are both linked, yet seperate to those of how permissive commons may be used to help pizza shop owners sell pizzas they can make, on their own websites; or how, to produce accessibility to knowledge about our biosphere, flora, fauna and all sorts of things in it; alongside how to publish trusted information about where the local civic amenities are, as may be useful for people in the area.
Permissions play a role in each case. The alternative of ‘open data’ from a lay perspective may be considered to suggest; that an agent can consume the open data provided by some authority, perhaps make changes to it to suit some form of agenda; and then republish it as an authoritative source.
It is not only troublesome in low-risk use-cases, but also dangerous in others.
Without the means to consume ‘knowledge’ or ‘information’, as does relate to a series of social frameworks relating to trust rationale, data is data, open or otherwise; ‘open data’ is far less useful than socio-cyber solutions that can be put to use to build trust-frameworks for commons and real-world tasks.
2. Authorities: Group Agents & write, edit & append permissions
Agent Identifiers
The ability to create a record is something that all persons should reasonably be made able to do; both as expressed persons (meaning — real-names used) and through means of psuedo-anonymity; which is to say, whilst not everyone needs to know everything. There are also attack vectors employed through the use of fake accounts, and this is also an important issue to address.
Bad actors sully the means for others to make use of resources to be enriched.
Currently, there’s an array of ways that agent identifiers are created; yet most of these methods now poorly support the means to maintain hygiene online.
In a great many use-case examples relating to commons, there have traditionally been nominated custodians or stewards.
One way i try to explain this is by considering the processes involved in the creation of a Church, Library, Mechanics Institute or University.
Stonemasons and such, would undertake the activity of building, the building.
It is most likely that they were paid for their labour to do so; but once their role in creating the civic infrastructure was done, the management of it was handed over to someone else.
Without a library, there would be no easy place to find or read a book; or in consideration of the concept more broadly; the means to learn, pray or live.
Those who made this infrastructure were not expected to extinguish their own lives for having done so; and, they were acknowledged for their works by some form made available for historical purposes if nothing else.
In consideration for how this associates to the concept of ‘write permissions’, the principle is that most forms of ‘commons’ has some form of custodianship framework. An example of the importance of this might be considered in relation to the use-case of making the discovery of public toilets available online where it is preferable that a means to ensure results are properly qualified.
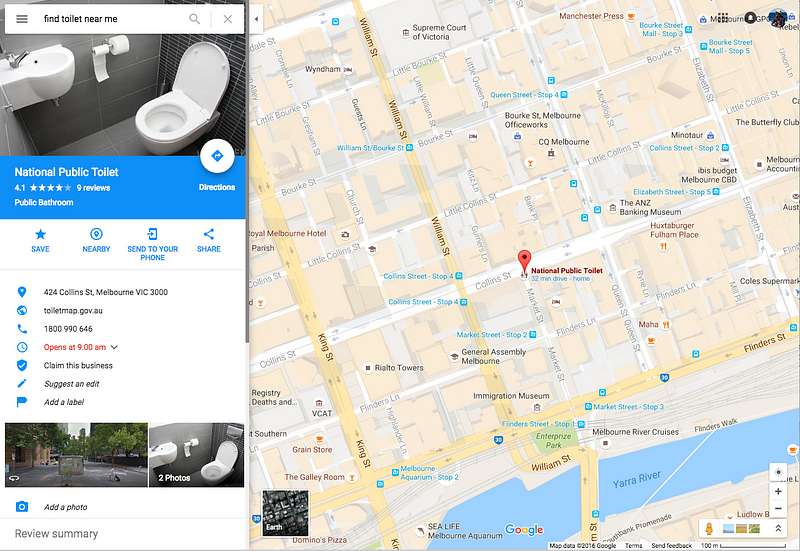
Search result Aug 2016 for ‘public toilet’

The Public Toilets example is similar in nature to that of the needs for programs such as Neighborhood Watch, a community program that seeks to provide a social means to help people who need to find a safe place to go.
In both cases, it is important that the resources found online have the backing of a community based custodial to ensure safety for those who use the facility.
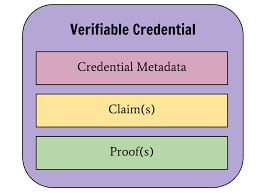
Verifiable Credentials Data Model 1.0
What we developed in W3C Credentials CG was a set of tools that could be used to verify how one particular agent, such as a trusted institution, was able to make a set of statements that could in-turn be consumed by others as a series of trustworthy informatics resources; as required to support trustworthy, decision makers.
Therein; the consideration of ‘permissive commons’ as distinct to ‘open data’, seeks to attend to the underlying reality that the way ‘commons’ are managed and made discoverable; does indeed relate to, a complex web of permissions that whilst indirectly considered in the somewhat misleading concept of ‘open data’; does in-fact relate to a set of supportively permissive practices. By refining the declarations of how this is (better) achieved, commons becomes more usefully available; and participatory engagement is in-turn encouraged.
3. Format
3.1 Linked Data & URIs
The practice method for publishing Permissive commons is best done by rendering resources in linked-data RDF related formats; with or without the use of DID based URIs.
What are DID’s?
DID technology is poorly documented as a consequence of intentional decision making practices brought about whilst the work was getting (funded) done. In-essence, the documentation today speaks of identity; whereas DIDs are also useful for supporting identified, entities; whereby (machine readable) statements are made with the use of cryptographic instruments.
{
"@context": ["https://www.w3.org/2019/did/v1", "https://w3id.org/security/v1"],
"id": "did:example:123456789abcdefghi",
...
"publicKey": [{
"id": "did:example:123456789abcdefghi#keys-1",
"type": "RsaVerificationKey2018",
"controller": "did:example:123456789abcdefghi",
"publicKeyPem": "-----BEGIN PUBLIC KEY...END PUBLIC KEY-----\r\n"
}, {
"id": "did:example:123456789abcdefghi#keys-2",
"type": "Ed25519VerificationKey2018",
"controller": "did:example:pqrstuvwxyz0987654321",
"publicKeyBase58": "H3C2AVvLMv6gmMNam3uVAjZpfkcJCwDwnZn6z3wXmqPV"
}, {
"id": "did:example:123456789abcdefghi#keys-3",
"type": "Secp256k1VerificationKey2018",
"controller": "did:example:123456789abcdefghi",
"publicKeyHex": "02b97c30de767f084ce3080168ee293053ba33b235d7116a3263d29f1450936b71"
}],
...
}
note comments made in: Comms & Security: privacy vs. dignity and The article ‘tools that can help naturalise the web’ goes into the mechanics of how this works in more detail.
Part of the underlying requirements is to ensure resources are made available in a format that is addressable via a URI. DID’s provide a means to decentralise the custodianship of a URI as to decouple the authoritative source(s) from a traditional approach that would require a HTTP based URI.
3.2 Made for Decentralised use
There are an array of DLT solutions that are becoming available (post blockchain, blockchain related tech) that include DHT methods amongst the many. Early W3C CG works uplifted MIT HTTPA works with WebDHT, whilst later works evolved to consider WebLedger solutions. Whilst it is envisaged that standards will emerge in this particular area of protocol innovation; the underlying principle is that the storage framework should be able to support decentralised and therefore local use.
The easy explanation for lay people, is that it works kinda like a blockchain or torrent; in that, an announcer provides discovery for the information that is made downloadable, as to be able to make use of it locally.
Amongst the best illustrations of solutions that have been made to work currently, is that which has been produced by the internet archive; called dweb (source). dWeb implements the internet archive using IPFS, WebTorrent and wolk; whilst gun.eco (a graphDB) and the holochain protocol (as distinct to holo, the company, or commons engine as a holo related initiative) are amongst the notable protocol solutions DID technology tries to harmonise. I am not aware of any ‘standard’ (IETF presumably) protocol solution; although the topic has been explored for sometime via the IRTF Information Centric Networking research group (IRTF is associated to IETF); and some components of the required solutions have been made IETF RFCs as a consequence of community group works facilitated by way of W3C-CGs.
Importantly; the solutions that will work, need to support RDF or moreover; the principles underpinning semantic web ecosystems. Whilst DID documentation is in my mind, poorly produced; the solutions framework is intended to support otherwise not-updated semantic web documentation that moreover expressly refers to services provided solely, over HTTP.
3.3 Support for Version Control (Provenance & History)
There are many use-cases where the versions of; and temporal notations of, a resource becomes important for the means and derivative insights brought about by its use.
As such; The considerations have a set of real-world implications in relation to law, but also many other things and practicalities.
Whilst the continual improvement of knowledge is most certainly desirable, or moreover a ‘must have’, in terms of technical functional qualities; as it is likely to be the case that erroneous decisions may be made on the basis of false, misleading or bad data; the answer to this problem isn’t simply the means for the issue to be scrubbed from history (as to form a dissociative relationship to any implications). Relations naturally change overtime, intrinsically forming a form of temporal ontologically discernible quality, that by simply updating a singular record in a manner that makes the formerly relied upon version entirely unavailable, cannot support.
One reason why it is important, is that changes to URI sourced materials may in-fact substantially change its meaning, as may in-turn act to pervert sense making.
People have the right to change their minds; their position, on any given topic… Indeed moreover it’s expected of people who are considered to be reason-able.
The practice of learning implicitly relates & relies upon the capacities of a system, to support the notion of evolution of understandings, as to support the concept of understanding, as is employed improve upon prior temporal states. In socially-applied informatics environments, the provenance of inter-related ‘ripple effects’ is of importance to relations denoted as observations (or ‘observers’) of other agents, who have at some time interacted with it.
4. Societal Custodial relations & Stewardship
(Data|Information | Knowledge) ‘Commons’ are essential tools to support means through which natural agents are made able to engender their own sense of wisdom, that may only then, become in-turn, a shared resource.
In the Natural world; this is often articulated via identified groups, such as is the case with a nations system of government. Therein; the articulation of laws in societies have a material and custodial relationship to Acts of Parliament; and thereafter, relationships to any judgements and common-law. Permissive commons as a cyber-physical toolset in-turn supports the means to extend the acts of real-world natural agents to support (and influnce) analysis practices. One example of this is that some of the permissive commons assets available, might be done to associate two otherwise foreign uses of similar terms, with some sense of discernible logic (ideally both machine and human readable, as may be achieved per point 3) as to support the means for others to comprehend such things as the differences between ‘copyright’ in one region, to the definition formed by laws in Another.
As such, one might imagine a time where the votes made by parliamentarians (and any notes that may relate to their vote) could be made in a digitally ‘minted’ format, that in-turn acts digitally to be a signatory to the introduction of that commons asset; and/or, the renewal of it. Yet also, thereafter, others may then in-turn form meaningful relations and inferences between those laws and considerations that are not necessarily ‘same as’ but ‘similar to’ others elsewhere; and in-turn, providing semantics explaining how & why.
Where the consideration relates, in-turn, to the practices of managing civic amenities; in countries such as Australia, it is the role of local government, otherwise known as councils or shires; whom by means of the Australian Constitution act as agents of state government to support the maintenance of these assets by way of tasks performed by employees of the local authority.
Members of the public are expressly invited to contribute or notify their local council if there is a problem; but, the ‘digital twin’ of the physical asset online, would be a permissive commons assets that is governed by the local council, and would most likely be governed through an integration with council systems, as to trigger updated information.
An example may be that of vandalism, or closure for some reason.
But the manner in how these informatics objects that are ‘commons’ are managed; is reasonably considered to need an authority. The availability of the afore mentioned, toilets, or safe spaces — need authorities involved for safety.
Another example may be the rules that are set-out and publicly available for Augmented Reality Applications; to ensure virtual game objectives are not encouraging children to play on roads or freeways; or conversely, that perhaps ‘virtual boundaries’ are able to be set-around safe areas like parks, for AR Play.
I envisage the means to create various constructs of ‘knowledge forests’ that interweave the voices of citizens, electronically; as resources for stewards to employ & be made accountable; as would relate to their roles of managing permissive commons. Semantic Web provides the sense-making linkages between informatics resources; DIDs help decentralise discovery and use, version control and permission systems help form trustworthy Semantics.
Therein; the authoritative chains are not, by design, intended to be globally centralised in any practical way; rather, the employment of standards and emergent protocols enable the creation of societal systems to extend support for cyber-physical relations to conform to real-world fiduciary relationships.
5. Artificial Intelligence
HBO Silicon Valley ‘not hotdog’
Perhaps of most importance today, is the array of considerations brought about by the instrumental use of ‘data’ for software agents, or AI. The means to ensure the role & responsibility of parliamentarians, amongst others, has never before become so important, as is now the case, as required, to uplift the purposeful role of humanitarian tenure in any role; in an age where artificial intelligence systems are going to be of enormous influence.
The same consideration is made for all members of our human family; yet, it seems pointless if those consider themselves most importance as societal leaders, fail to understand how ‘taking the easy road’ may now poorly affect others in a way that is not the same as any human based systems framework, worked before.
I state it to be the case, clearly; that our information systems today do not support anonymity. As such; they are not able to fully support entirely private use. Indeed also, this principle is reasonably cemented in natural laws, as may be examined using science; in manners now significantly enhanced with social graph technology as to explore relationships between the means to discern inferences, and the effects of actions as is examined as formative interference patterns that have a direct and inferred relationship to causality.
The question that is brought about; is whether and how to make best use of the opportunity, to make something that supports the distribution and curation of knowledge apparatus, accessibility, and how it is to be managed.
How can we employ ICT strategies, to in-turn promote capacity that enriches usefully evolved bodies of knowledge, as to best support the notion of mandate; and, how can resources used, be considered trustworthy, by courts.
Systems are reliant upon agreements internationally, how should permissive commons be made to work; for the betterment of all stakeholders involved.
The informatics systems that are being defined on way or another (but not necessarily as commons) is not solely about text or numeric data; but also, informatics structures that are used to discern aspects of reality in many ways.
One such way is rich-media, where the EU funded Mico Project made headway to standardise tools that could lead to services that could democratise the use of AI, for the analysis of rich media assets. The perceived value of this emergent field was illustrated by the US TV Show Silicon Valley.
One of the stories in this show illustrates a narrative about a computer vision tool that is first funded as a tool to identify food.
HBO: Silicon Valley Season 4 Episode 4 ‘Seefood Technologies and ‘Not Hot Dog’
What this illustrates; is that, no-matter whether or not any choices are made, the vast global silo’d infrastructure that is moreover converged into the community of california (and Californian law) have enormous data capabilities to see what is actually going on. These tools are applied to media online, and the derivative services made available via a proprietary API.
This does not best support the democratisation of AI
The decisions that can be made, in a business systems based vacuum. The alternative of ‘permissioned commons’ could limit and lesson means through which people are harmed; whether wilfully, negligently or due to practices of malfeasance; the factors that need to be addressed as to best respond to the issues brought about by ‘AI’ include factors or circumstances; that will otherwise lead to poor or false belief’s & statements. This pervasive problem is likely to in-turn influence public records, including those such as the hansard. So, there’s a question about the relationships between matters of fact, as are able to be assessed by someone due to the ever growing surveillance capabilities consumed as a raw resource, for AI. Importantly therein also, the availability of business systems to support work being done.
One way to address this problem is to form a Micropayments Standards: An Economic Imperative for the Knowledge Age, noting the practice of doing so is in-effect the same as the tactical process required for permissive commons.
AI capabilities are usefully able to be employed; as to discern or make distinct, the means or comprehension, to distinguish between actors who are known to have known what; in relation to the commission of wrongdoings. This helps to discern intent in relation to a wrongful act, but only if it’s a supported function. To do so, my belief is in a knowledge banking industry, yet today this seems most likely to occur as a consequence of new projects by facebook or similar. Whilst the Libra Association couples the existing capacity of those such as facebook to update and improve upon its global graph; a globally democratised alternative, would require much more work to evolve.
Yet the principle capacity to discern the difference between someone who knew better, and those who were reasonably not able to know, critical and instrumental pieces of information; is able to be demonstrated by those such as facebook (and google), today. In relation to the use of these sorts of systems by AI agents, it is not simply about the means to understand what is known; but also what is not. Permissive commons is instrumental to forming a non-corporatised approach, to how this is facilitated for our natural world.
Finally — AI & Intellectual property.
In the show, Silicon Valley, it is later found that the ‘seefood technologies’ not hot dog app; is unable to identify any other food than hotdogs. It is then found to be best able to be repurposed for commercial purposes, to identify explicit materials online.
HBO Silicon Valley ‘not hot dog’ app repurposed
International trade is built upon the works of others that become protected by law by terms relating to Intellectual property. Whilst there could be a system that paid a nominal amount, such as $0.00001 every time something useful; is made use of, this capacity doesn’t exist in business systems online today.
The consequence is competition between subject matter experts, rather than being able to forge cooperative alliances working collaboratively towards the realisation of specified goals. Consequentially, we consume more energy, to form progress…
Perhaps as a defensive tactic, there is a call to recognize AI as an inventor.
I think more simply put, if you had a global company that was able to read and collate all the documents produced about innovative and potentially valuable ideas from all across the world; would you make a bot that directed key staff, partners and alliances towards an augmented & AI Curated experience that may help them get a patent on those ideas first?
Would it be consistent with the principles of good corporate citizenship, to let foreigners have the opportunity to get those economic opportunities in place first? In the current ecosystems, unlike space, the answer is reasonably, no.
Governments could set-out a set of principles for Cyberspace, but today that doesn’t exist. I have registered ‘thecharter.eco’ but its an idea not a useful tool.
As part of a ‘permissive commons’ approach, it is entirely possible to deliver a set of ontological resources that consider our ecosphere and the impact cyber-physical systems have on all things real, as are part of our natural world.
I am interested in exploring this idea; and i hope others will be too…
6. Democracy, Citizenship & the role of Web Worker Rights
In-order to make permissive commons work to best effect; the concept would require an international network of domestic systems of inter-governance.
Should present infrastructure be better ‘democratised’, then the outcome could not only be the creation of ‘more jobs’; but also — improved means for the governance of nation built upon a system of democracy that grew from such concepts as ‘rule of law’.
In our internationally competitive environment, we have not yet applied considerations of how project frameworks like BOT/DBOT, or public-private partnerships, used to build the libraries of the past; could be used to address our means to attend to the importance of critical, cyber-social infrastructure, as is required by mankind. In my opinion, it would be enormously short-sighted, no-matter the difficulties involved in garnishing an effective basis for informed decision making, to not do so, as can be made, to be brought about.
The competition is not between the aristocrats and ‘old money’ tribes whose castles of wealth at times form adversarial interests to the common citizen;
Rather, this competition is arguably about the relevance of a nations government at all. Without domestic means to support sense making and therein mandate, cyber-physical systems threaten reemergence of old problems via cyber domains.
The competitive forces are international in nature, not local. In terms of trade, having the truth called out in secret overseas, is much worse than the cost of addressing the underlying issues on a domestic basis.
The implications to how why it is important to attend to these issues should be reasonably universally understood; as to positively impact the lives of children EVEN THOUGH, their family members may have a position of importance, publicly. This nature of ‘permissive commons’ gets to the heart of how it is we can meaningfully and purposefully produce tools, to support human dignity.
The most awesome way i’ve seen this explained; is this short video,
new definition of a billionaire, “to positively impact the lives of a billion people”
Therein, Jason Silva ends his parable with the concept that the future definition of a billionaire, is a person who has positively impacted the lives of a billion people. With permissive commons, this is made far easier to achieve.
Permissive commons is an instrumental part of how we may best create a modern innovative medium, for the bewildering store of knowledge that has been fostered as to become useful real-world knowledge assets, by mankind.
The way this can be funded, is through the meaningful use of micropayments, yet the implication of bringing about a means to pay people who do valuable work in areas that support the evolution of our shared commons, leads to a situation where we need to think about anti-money laundering laws, or KYCC/AML.
When associating reasonably tiny fractions of a cent that contributes towards a persons means to be paid a wage; until a reasonable amount has been garnished by that contributor (ie: ~$xx per hour), then the means to form a practice method where mankind is encouraged to invest in works for the betterment of our world; rather than alternatives such as fake news, which are known to be of far more value to creators today.
- The ability to make use of the internet, is not truely free today.
- Civilians, are now considered in terms of their role as a consumer to be protected; rather than as natural world tenants, companies should serve..
The manifest converse reality is; that today, it’s their attention that’s being consumed as a resource, and that ‘open data’ frameworks have contributed to the drivers that now propagate many distinct fiction of reality; which are in-turn beneficially, complimentary to old ‘resource based economy’ method; pervasively employed to consume all natural resources, for (false) profits.
As a supplemental to the video above, Author Shoshana Zuboff in the video Age of Surveillance Capitalism: “We Thought We Were Searching Google, But Google Was Searching Us” illustrates her position on how the web works today.
Whilst the underlying purported concept of ‘consumer’ doesn’t really apply, as the global platforms that are related to this concept don’t really have competitors, so as there’s no ‘choice’, its not really about market alternatives.

Source: Visual Capitalist
If someone asks you to connect with them on facebook, you have to use facebook. If you leave facebook, you can’t take your ‘friends’ with you.
So, the concept of being a ‘consumer’ is not fit or proper, for many reasons.
- The customers of these sites are those who pay to display advertising. Therein, the first component of ‘costs’ relates to their income streams.
- People need to pay for the connectivity. In telecommunications terms this relates to a metric called ‘Average Revenue Per User’ or ARPU.
- People need to pay to buy the consumer electronics that are used to participate in society in a way that demands ownership of these tools; and,
- People are increasingly paying a significant additional fee to international companies who are providing valued services.
On top of all of that is the cost of living. So, energy, housing, food, health, etc.
These costs could be reduced to a average number, per hour which is like to be in dollars ($x/h), tens of dollars or perhaps hundreds or thousands of dollars when associated to wealthier people or legal personalities (companies).
Part of these costs could also consider consequential costs of false assumptions and the insurable benefits of improving the basis upon which decisions are made.
Another consideration worth thinking about, is the underlying nature of economics and how it is actually made to work. The purpose of money is exchange. So that people who work to do things that are of social value are able to exchange ‘goods and services’ with others.
If a vast group of work types are considered to be ‘free’, this damages society.
I am in no way suggesting that someone should be able to make unfair requests; indeed quite the opposite, but there is a balance to be forged.
Therein; in seeking to align the above considerations with the concept of permissive commons, it must be noted that the world as we know it wouldn’t have been made able to work; as we now benefit from, if the information we knew and had available to us freely; such as language, and the means to discover places and place names; was subject to economic gatekeepers by a few knowable entities who governed those ‘knowledge assets’ world-wide.
Permissive commons, is about forming a cyber-physical solution to support the continuance of those underlying principles as are required for mankind.
It is reasonable to consider that the work of someone to do stuff that’s good for humanity, is something that should be supported.
Therein, as an example; if someone fixes a bug in software that may expose IoT infrastructure to exploitation, their ‘fix’ might positively impact billions of devices; and only take, a relatively short time to achieve (ie: hours, days or weeks).
Say, it is their profession to do these sorts of things; and that, it’s how they support their families and their means to learn and maintain their skills.
As such, they calculate their cost per hour to be about $500 for this sort of work, so if their work is found to fix a problem and took 20 hours, then that’s a cost of about $10,000.
If the means to articulate this cost to its use on a billion devices, its not much at all per unit that’s attributed in-order for them to get paid for that work. Therein, the consideration is that as a consequence of the use of time which both supports contribution in addition to consumption; the opportunity to add to calculations basic levels of support for human activity, isn’t a bad thing.
To do so, would require standards and infrastructure solutions not present today.
The additional benefit is that if they’ve built in an exploit, then they’re also able to be made accountable for doing so, if it’s been done intentionally.
This is the sort of opportunity that’s brought about with permissive commons in a way that could be explored further; and its important government plays a role.
This is not to say that governments should be the sole provider, but rather regulatory frameworks play an important role. This concept ‘permissive commons’ seeks to ‘do away’ with survelliance capitalism in many useful ICT applications; and seeks to better articulates the concept now known as ‘open data’; as to better align what seems to be the underlying intent, with our modern needs, in our modern age; which in-turn, i suggest, needs a re:think.
IN SUMMARY: JOBS AND PERMISSIVE COMMONS
Today, there are no shortage of jobs to do, there’s a set of artificial boundaries that have been placed upon the means to pay anything for useful work. The consequence of this policy is that people who want to do good things for society and ‘stuff’ that positively impacts our biosphere; are now often paid far less, than those who knowingly do the opposite, this impacts societal value(s).
As to assist with considerations i’ve drafted some thought, that i’ve titled ‘Engineering Einstein’ whilst the underlying hope, is that we’d reinvent the kindness equastion at a time when its well known our biosphere, needs help.
The means to attribute ‘good work’ with income, needs to be addressed as part of the social factors that relate to how it is commons are produced and maintained. Much like the stonemasons building libraries, it didn’t mean they were paid, forever, every time someone sought to use the commons facility.
There are an array of distinct and differentiated business systems opportunities that can come about; if we have a little more faith, in humanity.
Conversely;
Without the means to articulate the spirit of humanitarian principles, as are in-turn rendered meaningful support by systems of governance; our means, as citizens, to get on with the job of cooperatively attending to issues, becomes unduly hampered.
If we build a ‘knowledge layer’ of permissive commons to the web, then not only are we made better equipped to build upon the knowledge artifacts distributed by others; but we are also better equipped to qualify what it is we’re most capable as knowledge agents, to render as services for others. The permissive commons frameworks, as does uplift open data, lod-cloud and similarly available systems today; enables a person to analyse themselves, or be permissively analysed by others, in relation to ‘known — knowledge’, to articulate accomplishment, capability and other semantic nuances attributable to a natural agent as are factors relating to trust. These systems are not intended to be ‘open’ but rather permissive, and requires permissive commons in-order to be made to work.
An alternative is facebook, but we can address these sorts of issues, and it starts with the production of tooling that is made to relied upon for an infosphere of permissive commons; and the way that may be used throughout our world. Whether or not these sorts of systems exist isn’t really a relevant, as it is most likely the case that even if we don’t do that, the engineered future of how things are made to work, will causally impacts us all using informatics.
We can choose to make sense-making a commercial asset, or define a system that is made to work that employs a set of principles i call ‘permissive commons’. One alternative is better for greed, the other for our biosphere.